HumorBench
Which LLMs Get the Joke? Probing Non-STEM Reasoning Abilities
Abstract
We present HumorBench, a benchmark designed to evaluate large language models' (LLMs) ability to reason about and explain sophisticated humor in cartoon captions. As reasoning models increasingly saturate existing benchmarks in mathematics and science, novel and challenging evaluations of model intelligence beyond STEM domains are essential.
Reasoning is fundamentally involved in text-based humor comprehension, requiring the identification of connections between concepts in cartoons/captions and external cultural references, wordplays, and other mechanisms. HumorBench includes approximately 300 unique cartoon-caption pairs from the New Yorker Caption Contest and Cartoonstock.com, with expert-annotated evaluation rubrics identifying essential joke elements.
Leaderboard
Performance of current models on HumorBench (as of July 2025)
| Rank | Model | Score (%) |
|---|
Score represents the percentage of humor elements correctly identified. See our interactive results viewer for detailed analysis.
Key Findings
- LLM progress on STEM reasoning transfers effectively to humor comprehension
- Models trained exclusively on STEM reasoning data still perform well on HumorBench, demonstrating strong transferability of reasoning abilities
- Test-time scaling by increasing thinking token budgets yields mixed results across different models in humor reasoning
- On HumorBench-hard, which features more complex examples requiring multiple reasoning steps or obscure cultural knowledge, no current LLM exceeds 50% accuracy
How HumorBench Works
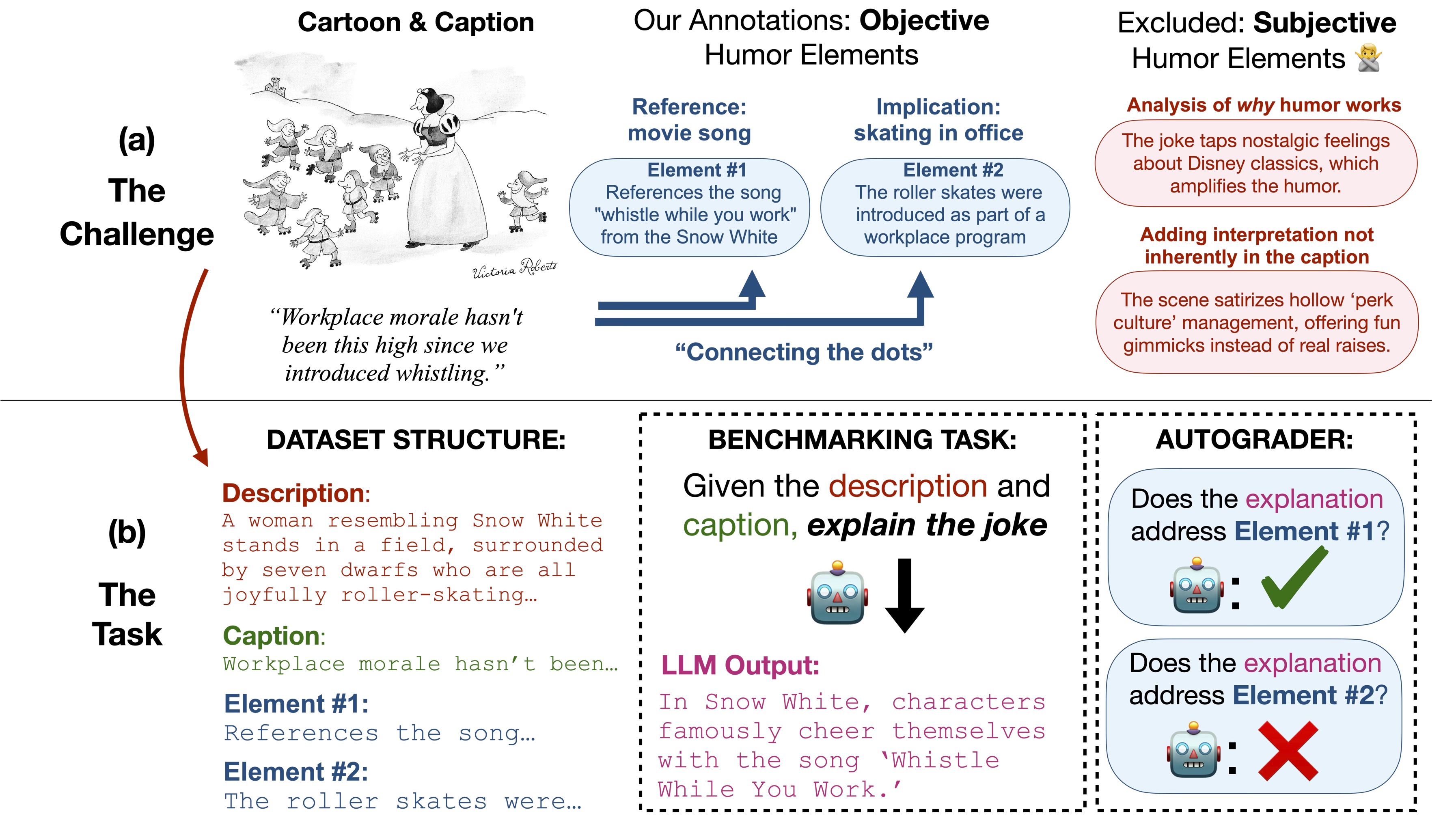
HumorBench takes a fundamentally different approach to evaluating humor understanding in AI. While previous benchmarks often conflate two distinct challenges—understanding what makes something intended to be funny (objective comprehension) versus finding it amusing (subjective appreciation)—we focus exclusively on the former.
The Task
Given a textual description of a cartoon and its caption, models must explain what the joke is, identifying the specific connections and mental leaps required to understand the humor. For instance, recognizing that "Death" playing chess references both the literal game and the metaphorical "chess match with death," or understanding how a swimming person might be interpreted as "groceries" from a shark's perspective.
What Makes HumorBench Different
- Objective vs. Subjective: We separate humor comprehension (understanding the intended joke) from humor appreciation (finding it funny). Our benchmark measures whether models can identify the factual elements that create the humor, not whether they align with human preferences about what's amusing.
- Expert-Annotated Elements: Each cartoon-caption pair is annotated with 1-3 concise "elements"—the essential objective components needed to understand the joke. These serve as a rubric for evaluation, ensuring consistent and fair assessment.
- Open-Ended Generation: Unlike multiple-choice formats that can hint at answers, models must generate free-form explanations, better reflecting real understanding.
- Sophisticated Humor: We use New Yorker Caption Contest winners and top Cartoonstock cartoons—sources known for dry, witty humor requiring cultural knowledge, wordplay recognition, and complex reasoning.
- Automatic Grading at Scale: Our LLM-based autograder achieves 92% agreement with human judges, enabling large-scale evaluation while maintaining quality.
This approach reveals that humor comprehension is fundamentally a reasoning task. Models must connect visual elements, caption text, and external knowledge—making the same kinds of logical leaps required in STEM domains, but applied to cultural and linguistic contexts.